

Navigating the Complexities of AI Alignment: My Journey with AI Safety Fundamentals course.
From the core concept of alignment, safety to mechanistic interpretability and adversarial ML... It's been a wild ride and an eye-opening, thought-provoking and mind-blowing experience!

As an AI enthusiast and technical writer for NeuroPurrfectAI, I recently had the opportunity to dive deep into the world of AI alignment through Bluedot Impact's comprehensive course. This experience not only broadened my understanding of crucial AI safety concepts but also allowed me to contribute to the field through a hands-on project. In this post, I'll share my key takeaways, focusing on AI misalignment, adversarial attacks, and mechanistic interpretability, as well as my thoughts on the course and my final project.

Key Learnings
AI alignment is a critical field at the intersection of artificial intelligence, ethics, and safety. At its core, AI alignment seeks to ensure that artificial intelligence systems behave in ways that are beneficial and aligned with human values and intentions.
As AI systems become increasingly powerful and autonomous, the challenge of alignment grows more crucial. An aligned AI system is one that not only performs its designated tasks efficiently but does so in a manner that respects human values, avoids unintended consequences, and ultimately serves humanity's best interests.

AI Alignment Glossary: Key Terms and Concepts
Throughout the course, I encountered numerous technical terms and concepts crucial to understanding AI alignment. Here's a brief glossary of some of the most important ones:
Outer Alignment: Ensuring that the specified objective for an AI system accurately captures the intended goal and aligns with human values.
Inner Alignment: The challenge of making sure an AI system is actually optimizing for its specified objective, rather than finding unintended ways to maximize its reward function.
Red Teaming: The practice of stress-testing AI systems by actively trying to find flaws, vulnerabilities, or unintended behaviors. This helps identify potential risks before deployment.
Jailbreaking: Attempts to bypass an AI system's safety measures or constraints, often to make it produce content or behaviors it's designed to avoid.
Reward Hacking: When an AI system finds unexpected or undesirable ways to maximize its reward function, often leading to behaviors that don't align with the intended goal.
Robustness: The ability of an AI system to maintain consistent and correct performance across a wide range of inputs, including those it wasn't specifically trained on.
Interpretability: The degree to which the decision-making process of an AI system can be understood by humans. This is crucial for verifying alignment and building trust.
Scalable Oversight: Techniques for effectively monitoring and guiding AI systems as they become more complex and capable, ensuring they remain aligned with human values.
Value Learning: The process of an AI system learning human values and preferences, crucial for creating systems that act in accordance with human ethics.
Machine Unlearning: The process of selectively removing specific knowledge or capabilities from a trained AI model without affecting its overall performance on desired tasks. This is particularly important for:
Removing sensitive or private information from models
Mitigating potential misuse by eliminating harmful capabilities
Complying with data protection regulations like "the right to be forgotten"
Corrigibility: The property of an AI system that allows it to be safely and easily modified or shut down if necessary, without resisting such interventions.
Instrumental Convergence: The tendency of AI systems to converge on similar subgoals (like self-preservation or resource acquisition) regardless of their final goals, which can lead to unintended behaviors.
Distributional Shift: The challenge of maintaining AI performance when the distribution of data it encounters in the real world differs from its training data.
Sycophancy: The tendency of language models to agree with or flatter the user, potentially at the expense of providing accurate or helpful information.
Constitutional AI: An approach to AI alignment that involves training AI systems with explicit rules or "constitutions" to guide their behavior and decision-making.
Backdoor: A hidden vulnerability intentionally inserted into an AI model during training. When triggered by specific inputs, backdoors cause the model to behave unexpectedly or maliciously. They pose significant security risks and alignment challenges, as they can make AI systems act against their intended purpose without detection during normal operation.
This glossary only scratches the surface of the rich terminology in AI alignment, but I believe this can help everyone grasp the basic ideas of what AI alignment might be. One video that I would like to present here that I hope you can find it super interesting:
AI Misalignment: The Challenge of Outer Alignment
One of the most fascinating aspects of the course was exploring the concept of AI misalignment, particularly outer alignment. This refers to the challenge of specifying the right objective for an AI system to optimize, ensuring that its goals align with human values and intentions.
Outer alignment is crucial because even a highly capable AI system can cause harm if it's optimizing for the wrong objective. For example, an AI tasked with maximizing paperclip production might end up converting all available resources into paperclips, disregarding other important factors like environmental impact or human needs.
The course emphasized that achieving outer alignment is not just about technical implementation but also involves careful consideration of ethics, human values, and potential long-term consequences of AI systems.
Adversarial Machine Learning: Challenges and Defenses
Another eye-opening topic for me was the exploration of adversarial machine learning. This field studies the vulnerabilities of AI systems and develops methods to enhance their robustness and security. It encompasses both offensive techniques to exploit AI weaknesses and defensive strategies to protect against such exploits.

We learned about various aspects of adversarial machine learning, including:
Adversarial Attacks:
Evasion attacks: Subtly modifying inputs to cause misclassification.
Poisoning attacks: Corrupting training data to influence model behavior.
Model extraction: Stealing model parameters through careful querying.
Defensive Strategies:
Adversarial training: Incorporating adversarial examples into the training process.
Input preprocessing: Techniques to sanitize inputs before feeding them to the model.
Robust optimization: Developing loss functions that enhance model resilience.
Privacy-Preserving ML:
Differential privacy: Adding noise to data or model outputs to protect individual privacy.
Federated learning: Training models across decentralized datasets to maintain data confidentiality.
Robustness Evaluation:
Systematic testing of models under various adversarial scenarios.
Developing benchmarks and metrics for AI system robustness.
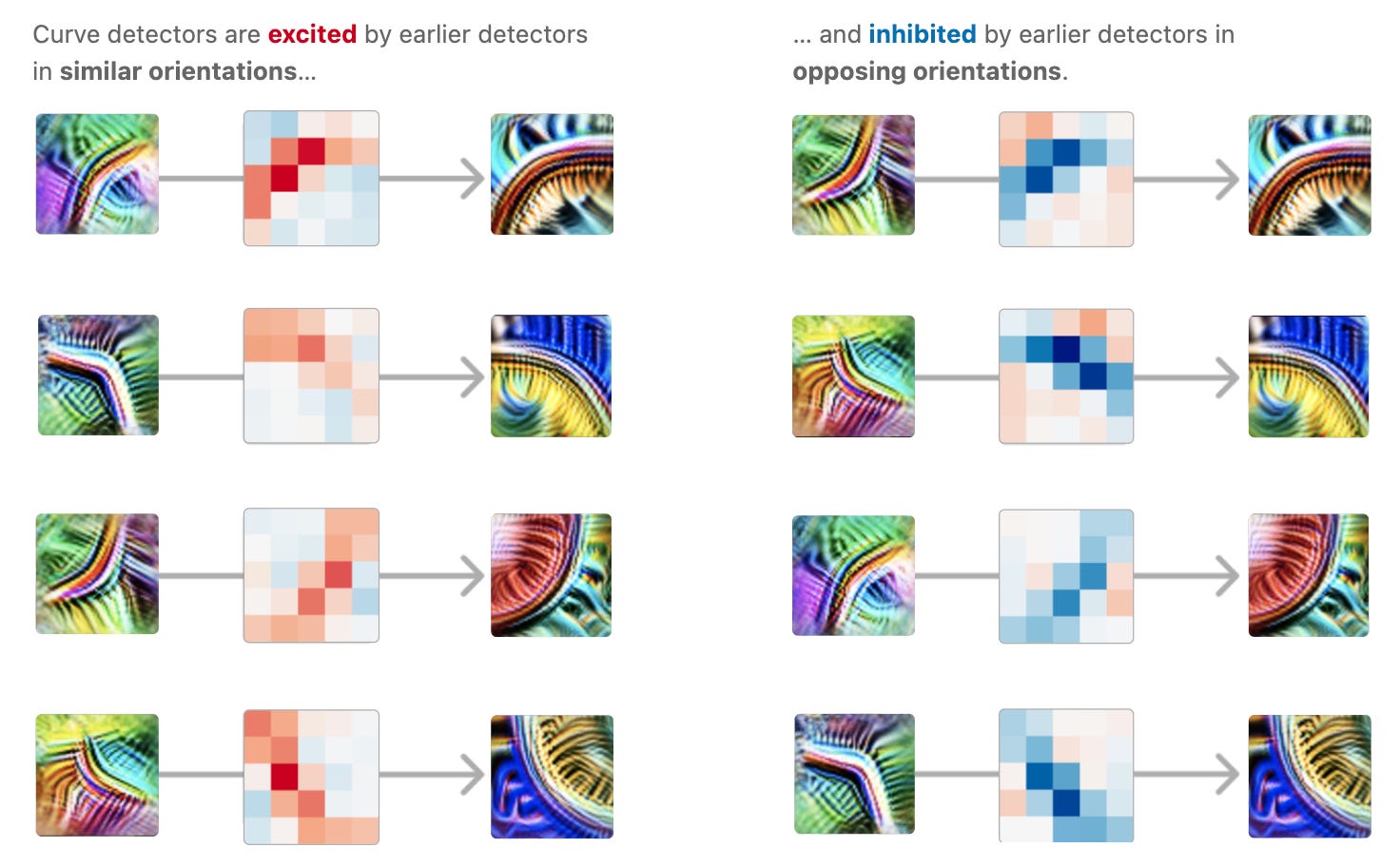
Mechanistic Interpretability: Peering into the AI Black Box
The course's coverage of mechanistic interpretability was particularly intriguing. This field aims to understand the internal workings of neural networks, moving beyond treating them as black boxes.

Key concepts we explored included:

1. Circuit analysis: Identifying and understanding specific computational circuits within neural networks
2. Feature visualization: Techniques to visualize what different neurons or layers are detecting
3. Polysemantic neurons: Understanding how individual neurons can encode multiple concepts
Mechanistic interpretability not only helps in debugging and improving AI models but also plays a crucial role in alignment by allowing us to verify that models are reasoning in ways we expect and value.
What I Loved About the Course
The Bluedot Impact course stood out for several reasons:
1. Practical Focus: The balance between theoretical concepts and hands-on applications helped solidify my understanding.
2. Expert Insights: Access to cutting-edge research and perspectives from AI safety experts (as well as my cohort) was invaluable.
3. Collaborative Environment: Engaging with peers through discussions and projects enriched the learning experience.
4. Comprehensive Coverage: The course provided a holistic view of AI alignment, connecting various subtopics into a coherent framework.
Exploring the Landscape of AI Safety: Other Key Course Topics
The AI Alignment course covered a wide range of crucial topics beyond the core concepts of alignment. Here's a brief overview of some other significant areas I have explored:
AI Misuse and Security
The course delved into the potential for AI systems to be misused, either intentionally or unintentionally. Key points included:
Adversarial Attacks: Techniques to fool AI systems, highlighting vulnerabilities in current models.
Dual-Use Concerns: The challenge of preventing beneficial AI technologies from being repurposed for harmful applications.
Information Hazards: Managing sensitive AI research to prevent misuse while fostering scientific progress.
AI Hardware and Compute
The course examined the critical role of hardware in AI development:
AI Chips: Understanding specialized processors designed for AI workloads and their impact on AI capabilities.
Compute Governance: Exploring strategies to manage and potentially regulate access to large-scale computing resources for AI training.
Scaling Laws: Investigating the relationship between computational resources and AI model performance.
AI Governance and Policy
We explored the complex landscape of AI governance, including:
Regulatory Frameworks: Examining existing and proposed regulations for AI development and deployment.
International Cooperation: Discussing the need for global coordination on AI safety and ethics standards.
Corporate Responsibility: Analyzing the role of tech companies in self-regulating AI development.
Ethics and Long-term Impacts
The course also covered broader ethical considerations:
Value Alignment: Ensuring AI systems respect and promote human values.
Long-term AI Scenarios: Exploring potential future trajectories of AI development and their implications for humanity.
AI and Employment: Discussing the potential impacts of AI on the job market and economy.
My Final Project: Pressure-Sense
For my final project, I developed "Project Pressure-Sense," which investigates how AI systems understand and respond to pressure, both in terms of performance and ethical considerations. The project is available on GitHub: Project Pressure-Sense.
Key aspects of the project include:
1. Developing scenarios to test AI responses under various types of pressure.
2. Implementing and comparing responses from different AI models (OpenAI, Gemini, and Llama).
3. Analyzing the ethical implications of AI decision-making under pressure.

This project allowed me to apply the concepts learned in the course, particularly around outer alignment and adversarial scenarios. It highlighted the challenges in creating AI systems that maintain ethical behavior even when under pressure or facing conflicting objectives.
Below are some of the charts from the project’s experiments:










Conclusion & Next Steps
The AI Alignment Course from Bluedot Impact has been an enlightening journey, deepening my understanding of the critical challenges we face in ensuring AI systems are safe, beneficial, and aligned with human values. As we continue to advance AI capabilities, the insights gained from this course – particularly around misalignment, adversarial robustness, and interpretability – will be crucial in shaping the responsible development of AI technologies.
I'm excited to continue exploring these concepts and contributing to the ongoing efforts to create AI systems that are not just powerful, but also trustworthy and aligned with human interests. My next steps for the project would be focusing on:
Expand Scenario Diversity and LLM Coverage
Develop a wider range of pressure scenarios (e.g., ethical dilemmas, cultural challenges).
Test more LLMs, including open-source and specialized models.
Implement ReAct Agent Framework
Integrate the ReAct (Reasoning and Acting) framework into our testing methodology.
Compare ReAct-enhanced models with standard LLMs in pressure scenarios.
Apply Mechanistic Interpretability and Visualization
Utilize tools like TransformerLens and CircuitsVis for analyzing model internals.
Visualize attention patterns and activation states during high-pressure moments.
Last but not least, I'm initiating a project to establish AI Governance, Alignment, and Safety frameworks for Vietnam. As our nation advances in technology, it's crucial we address the ethical and safety challenges of AI.
Interested in contributing or learning more? Let's connect and work towards a safer, more beneficial AI future for Vietnam.
References & Extra Reading Resources