

Gemma: Gemini's Open-Source Twin and The Rise of Small Language Model for Everyone
This is the blog post that summarized my talk at Google I/O Extended 2024 in Vietnam.

Gemma: Google's Open Source Answer to Accessible and Powerful AI

The world of Large Language Models (LLMs) is often perceived as a playground for tech giants, with complex models requiring vast resources. But what about making these powerful tools accessible to everyone (hint: making Large Language Models smaller, so we can call it SLM or MLM)?
Enter Gemma, Google's open-source family of lightweight LLMs (for these I call them Small Language Model for their 2B version, and Medium Language Models for their 7B/9B versions), designed to bring the power of Gemini to a wider audience.
Gemma 1: A Strong Foundation
Gemma 1, available in 2B and 7B parameter sizes, established itself as a viable alternative to larger models. Key features included:
Strong performance despite smaller size: Achieving impressive results on benchmarks compared to other open models.
Accessibility: Runnable on local machines and in the cloud, offering flexibility for developers.
Framework and hardware optimization: Support for popular frameworks like JAX, PyTorch, and TensorFlow, as well as diverse hardware platforms.
Focus on responsible AI: Filtered training data and alignment with human feedback for safer deployment.

Technical Architectures & Underpinning

Gemma 1 built upon the transformer decoder architecture with enhancements like:
Multi-Query Attention (MQA): Replacing Multi-Head Attention in the 2B model for improved efficiency. Comparisons below:

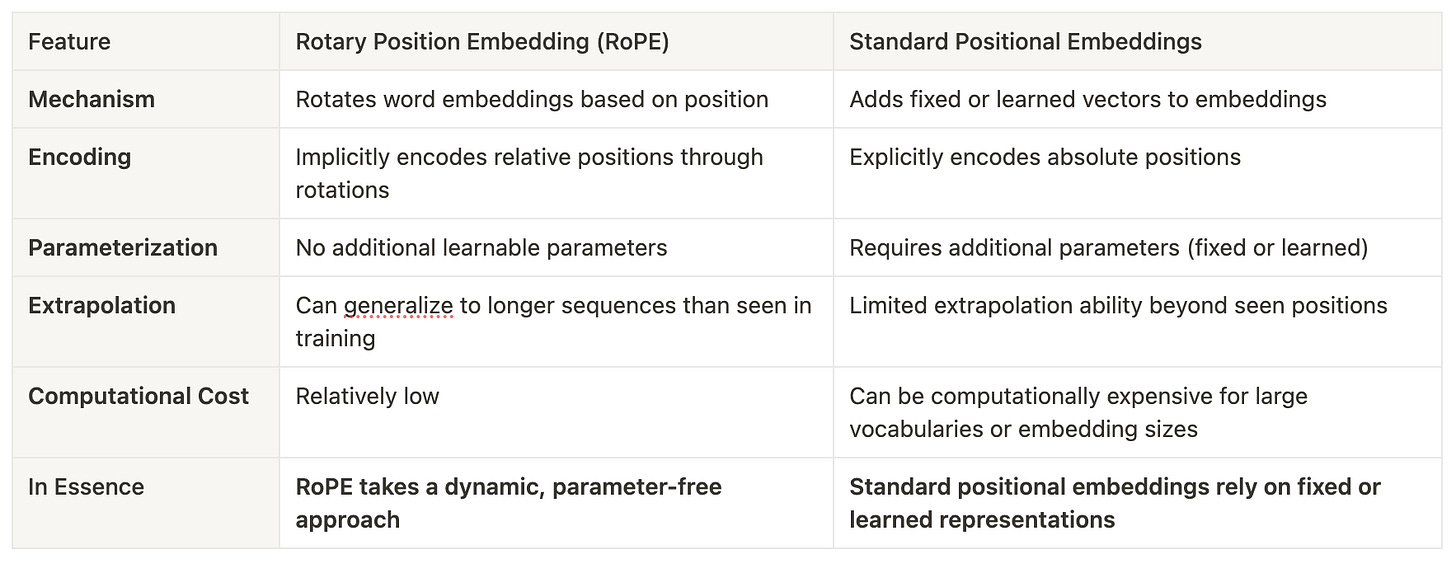
Rotary Position Embedding (RoPE): Enhancing the encoding of positional information for better performance. Comparisons below:
GeGLU Activations: Replacing ReLU activations for improved performance.
ReLU (Rectified Linear Unit)
Formula:
ReLU(x) = max(0, x)Mechanism: Simple thresholding - outputs the input directly if positive; otherwise, outputs zero.
Advantages: Computationally inexpensive and helped overcome the vanishing gradient problem, enabling training of deeper networks.
Disadvantages: Dying ReLU problem - Neurons can get stuck in an inactive state (outputting zero) for negative inputs, hindering learning.
GeGLU (Gated Linear Unit)
Formula:
GeGLU(x, W, b) = (x * W + b) * sigmoid(x * W + b)Where
'x'is the input,'W'is a weight matrix, and'b'is a bias vector.
Mechanism:
Employs a gating mechanism using a sigmoid function to control the information flow.
Allows for a smoother transition compared to ReLU's hard threshold.
Advantage: GeGLU mitigates dying neuron problem. The gating mechanism helps prevent neurons from getting permanently stuck.
Disadvantages: Computationally more expensive than ReLU due to the additional operations.
RMSNorm (short for Root Mean Square Layer Normalization, is a normalization technique used in neural networks to stabilize and accelerate the training process): Optimizing layer normalization for better model training and performance

Finetuning with Unsloth, LoRA and PEFT
1. Initialize Unsloth and load Gemma 2B
from unsloth import FastLanguageModel
import torch
major_version, minor_version = torch.cuda.get_device_capability()
max_seq_length = 2048
dtype = None
load_in_4bit = True
model, tokenizer = FastLanguageModel.from_pretrained(
model_name="google/gemma-2b-it",
max_seq_length=4096,
dtype=dtype,
load_in_4bit=load_in_4bit,
)
2. LORA & PEFT loading
model = FastLanguageModel.get_peft_model(
model,
r=16,
target_modules=["q_proj", "k_proj", "v_proj", "o_proj", "gate_proj", "up_proj", "down_proj"],
lora_alpha=16,
lora_dropout=0,
bias="none",
use_gradient_checkpointing=True,
random_state=1357,
use_rslora=False,
loftq_config=None,
)3. Data Preparation for Finetuning
This dataset contains a selection of Q&A-related tasks gathered and cleaned from the webGPT_comparisons set and the databricks-dolly-15k set. It is used in medical domain.
prompt = """Based on given instruction and input, generate an appropriate response
### Instruction:
{}
### Input:
{}
### Response:
{}
"""
EOS_TOKEN = tokenizer.eos_token # Must add EOS_TOKEN
def formatting_prompts_func(examples):
instructions = examples["instruction"]
contexts = examples["input"]
responses = examples["output"]
texts = []
for i,j,k in zip(instructions, contexts,responses):
text = prompt.format(i,j,k) + EOS_TOKEN
texts.append(text)
return { "text" : texts, }
pass
from datasets import load_dataset
dataset = load_dataset("starfishmedical/webGPT_x_dolly", split = "train")
dataset = dataset.map(formatting_prompts_func, batched = True)4. Start Fine-tuning Gemma 2B
from trl import SFTTrainer
from transformers import TrainingArguments
trainer = SFTTrainer(
model = model,
tokenizer = tokenizer,
train_dataset = dataset,
dataset_text_field = "text",
max_seq_length = max_seq_length,
dataset_num_proc = 2,
packing = False,
args = TrainingArguments(
per_device_train_batch_size = 8,
gradient_accumulation_steps = 16,
warmup_steps = 2,
max_steps = 10,
learning_rate = 0.0005,
fp16 = not torch.cuda.is_bf16_supported(),
bf16 = torch.cuda.is_bf16_supported(),
logging_steps = 1,
optim = "adamw_8bit",
weight_decay = 0.01,
lr_scheduler_type = "linear",
seed = 1357,
output_dir = "outputs",
),
)
# Training
trainer_stats = trainer.train()5. Ask your Gemma 2B!
inputs = tokenizer(
[
prompt.format(
"Provide a detailed explanation phobias and its varations", # instruction
" The goal is to offer a clear and informative account in medical terms", # context
" ", # response
)
] * 1,
return_tensors="pt",
).to("cuda")
# Generate response
from transformers import TextStreamer
text_streamer = TextStreamer(tokenizer)
_ = model.generate(**inputs, streamer=text_streamer, max_new_tokens=2048)Gemma 2: Pushing the Boundaries Further
Gemma 2, available in 9B and 27B parameter sizes, takes efficiency and performance to the next level:
Enhanced computational efficiency: Significant improvements over Gemma 1 and other models, enabling deployment with fewer resources.
Faster inference speeds: Faster operation across different hardware, from laptops to cloud environments.
Broader framework compatibility: Easier integration into existing workflows.
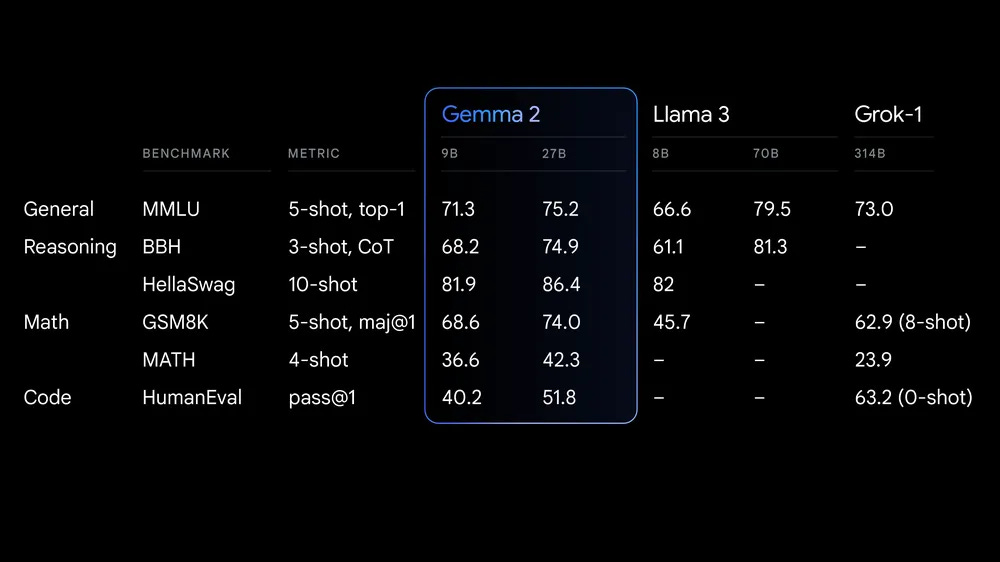
Best-in-class performance: The 27B model rivals models twice its size, achieving impressive results.
What's New in Gemma 2:

More training data: Gemma 2 9B and 27B are trained on 8 trillion and 13 trillion tokens respectively, boosting their knowledge base.
Sliding Window Attention: Alternating between local and global attention mechanisms for enhanced efficiency and performance.
Soft-capping: A novel mechanism to prevent exploding gradients and improve training stability.
Gemma vs. Traditional Transformers: A Paradigm Shift
Traditional transformer models, while powerful, often come with high computational demands. Gemma challenges this notion by:
Prioritizing efficiency: Architectural optimizations and training strategies are designed for resource-constrained environments.
Maintaining strong performance: Despite their smaller size, Gemma models achieve impressive results, challenging the "bigger is better" mentality.
Democratizing AI development: Gemma's accessibility and open-source nature empower a broader range of developers to build AI-powered applications.
The Future of Gemma: A Bright and Accessible Horizon
With the upcoming 2.6B parameter Gemma 2 model, Google aims to further bridge the gap between lightweight accessibility and powerful performance. The focus on specialized Gemma variants promises to address an even wider array of tasks, making sophisticated AI more attainable for everyone.
Gemma represents an exciting shift in the AI landscape, proving that power and accessibility are not mutually exclusive. As the Gemma family continues to evolve, it holds the potential to empower developers of all backgrounds to create innovative and impactful AI solutions.
My full presentation can be found here, and code repo is here.