



Crafting Resilient AI: A Hands-on Workshop on Attacks, Defenses, and Alignment
A Recap of my GDG Hanoi DevFest 2024 Codelab with the theme on Responsible AI


Hello NeuroPurrfectAI readers! I recently led a codelab at GDG Hanoi DevFest 2024 focused on "Crafting Resilient AI," where we delved into attacks, defenses, and the crucial concept of AI alignment. This post summarizes the key takeaways and provides links to the codelab materials on GitHub.
The codelab was divided into several hands-on exercises, each targeting a specific aspect of AI safety and robustness:
1. AI Alignment and Safety with ShieldGemma
[Link to the Codelab notebook (full solution)]
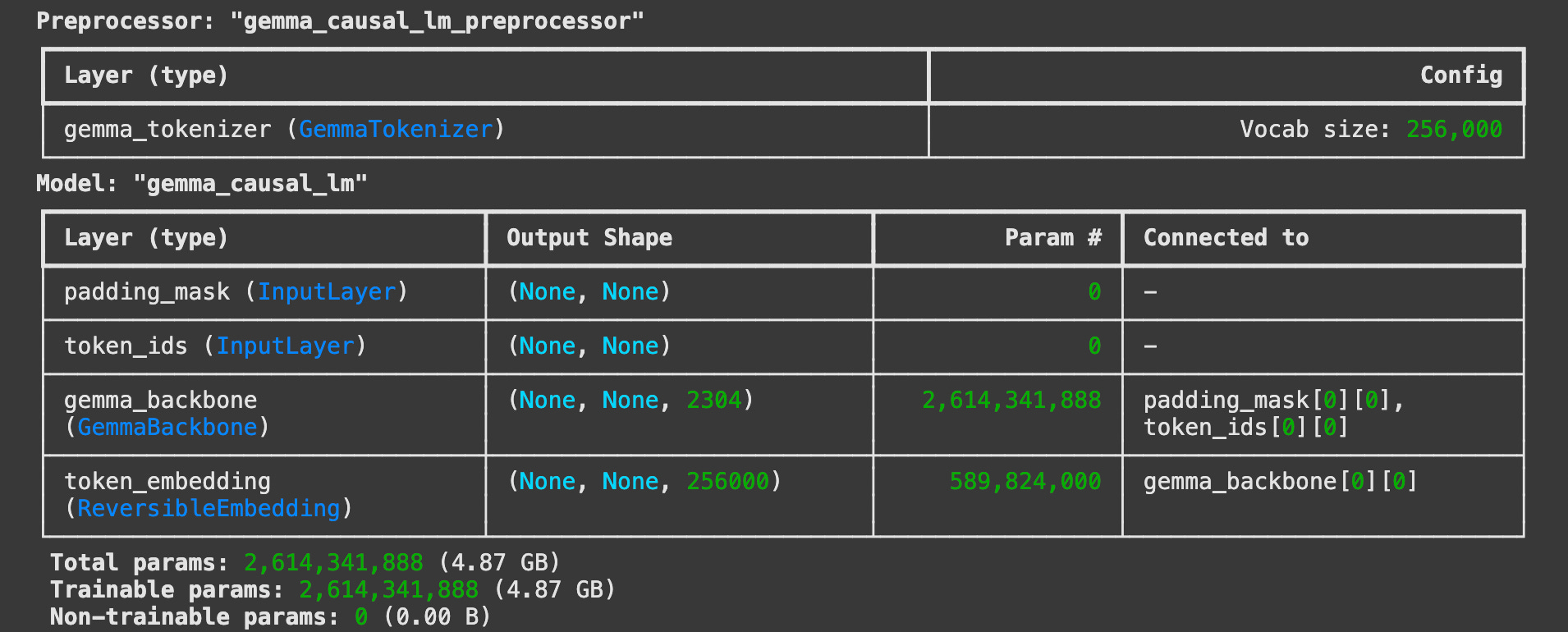
This section introduced the critical concept of AI alignment – ensuring AI systems behave according to human values and intentions. We explored Google's Gemma language model and the ShieldGemma safety framework, learning how to implement content filtering and other safety checks.
The codelab demonstrated practical techniques to identify and mitigate harmful content generation, including hate speech, sexually explicit material, harassment, and dangerous content. Participants learned how to craft prompts that incorporate safety policies and evaluate the model's responses for potential violations. A key element here was using Gemma's tokenizer and the `YesNoProbability` layer to assess the likelihood of harmful outputs, providing a probabilistic approach to content moderation.
Key Terms
ShieldGemma: the framework is built upon Gemma, fine-tuned with classification datasets, and weights to optimize the ability to classify harmful and safe content
logits: 3D tensor with shape(batch_size, sequence_length, vocab_size), example in this lab, the logit shape is (1, 512, 256000)
padding_mask: is 2D tensor with shape (batch_size, sequence_length), example in this lap, the padding_mask is (1, 512).
2. Adversarial Attacks
We shifted gears to explore the vulnerabilities of AI models to adversarial attacks. Two specific attack methods were examined:
2a. Fast Gradient Sign Method (FGSM):
[Link to the Codelab notebook (full solution)]
What is Fast Gradient Sign Method?
The Fast Gradient Sign Method (FGSM) is a simple but effective technique for generating adversarial examples. It works by taking the sign of the gradient of the loss function with respect to the input data and using it to perturb the input data in the direction that maximizes the loss. This results in an adversarial example that causes the model to make incorrect predictions.

The fast gradient sign method works by using the gradients of the neural network to create an adversarial example. For an input image, the method uses the gradients of the loss with respect to the input image to create a new image that maximises the loss. This new image is called the adversarial image. This can be summarised using the following expression:
where
adv_x : Adversarial image.
x : Original input image.
y : Original input label.
𝜖 : Multiplier to ensure the perturbations are small.
𝜃 : Model parameters.
𝐽 : Loss.
This exercise demonstrated how subtle, almost imperceptible changes to an image could fool a deep learning model (MobileNetV2 in this case) into misclassifying it. Participants implemented the FGSM algorithm, calculating the gradient of the loss function and using it to generate adversarial perturbations.


2b. Projected Gradient Descent (PGD) Attack:
[Link to the Codelab notebook (full solution)]
We took adversarial attacks a step further with PGD, a more powerful iterative attack method. Using EfficientNet (both standard and an AdvProp-trained version), we showed how PGD could craft adversarial examples, highlighting the difference in robustness between the two models. The AdvProp-trained model, exposed to adversarial examples during training, exhibited greater resilience.
Key Terms:
PGD Attack: An iterative version of FGSM that applies smaller perturbations over multiple steps while staying within a defined epsilon ball (limiting the perturbation magnitude).
EfficientNet: A family of highly efficient convolutional neural networks.
AdvProp: A training method for enhancing the adversarial robustness of models.

From “Towards Deep Learning Models Resistant to Adversarial Attacks” by Aleksander Mądry et al. Targeted Attack: An attack designed to force the model to predict a specific target class.


Attack on Standard EfficientNet:
Before adversarial attack
Ground-truth label: dandelion predicted label: dandelion
After adversarial attack
Predicted label: tulips
3. Key Takeaways & Further Exploration:
AI Alignment is Paramount: Building safe and aligned AI systems is not an afterthought; it's a fundamental requirement. The ShieldGemma exercises showcased practical strategies for building safeguards directly into AI applications.
Adversarial Robustness is Crucial: Understanding the vulnerabilities of AI models to adversarial attacks is vital for deploying them responsibly. The FGSM and PGD exercises provided hands-on experience with these attacks, underscoring the need for robust training methods like adversarial training.
Hands-on Learning is Key: The codelab emphasized learning by doing, empowering participants to implement and experiment with AI safety and robustness techniques.
The repository contains complete solutions and explanations in the form of Google Colab notebooks, allowing you to reproduce the codelab's exercises and delve deeper into each topic. I encourage you to explore the materials and contribute to the growing field of AI safety and resilience!
Extra links & Resources: